Ken Jin's Blog
Reflections on 2 years of CPython’s JIT Compiler: The good, the bad, the ugly
5 July 2025
This blog post includes my honest opinions on the CPython JIT. What I think we did well, what I think we could have done better. I’ll also do some brief qualititative analysis.
I’ve been working on CPython’s JIT compiler since before the very start. I don’t know how long that is at this point … 2.5, maybe almost 3 years? Anyways, I’m primarily responsible for Python’s JIT compiler’s optimizer.
Note that at this point of time, the JIT is still experimental. This means it’s not ready for prime time yet: this blog post may go out of date fairly quickly!
Here’s a short summary:
The good:
- I think we’re starting to build a community around the JIT, which is great.
- The JIT is also teachable. We have newcomers coming in and contributing.
Could use improvement:
- Performance
- Inaccurate coverage of the JIT
Good: A community-driven JIT
CPython’s JIT is community-driven at this point. You may have heard of the layoffs at Microsoft affecting the Faster CPython team. However, my underestanding is that from the very start, the JIT was meant to be a community project.
This wasn’t always the case. When the JIT started out, it was practically only Brandt working on the machine code generator. I had help from Mark (Shannon) and Guido in landing the initial optimizer, but after that it was mostly me. Later I got busier with school work and Brandt became the sole contributor to the optimizer for a few months or so. Those were dark times.
I’m really happy to say that we have more contributors today though:
- Savannah works on the machine code generator, reproducible JIT stencils, and sometimes the optimizer.
- Tomáš works on the optimizer and is a codeowner of it!
- Diego works on the machine code generator to improve it on ARM, and sometimes the optimizer.
- We also have various drive-by contributors. Zheaoli, Noam and Donghee are names that I remember. Though I’m definitely missing a few names here.
This community building was somewhat organic, but also very intentional. We actively tried to make the JIT easier to work on. If you dig up past discussions, one of Mark’s arguments for a tracing JIT was easier static analysis. This easiness isn’t just that it doesn’t require a meet or join in general or that it requires only a single pass, but more that static anlaysis of a single basic block is easier to teach than a whole control-flow graph.
We also actively welcome people to work on the JIT with us. CPython doesn’t have much optimizing compiler expertise interested in working on the JIT. We have some compiler people, but the subset of those interested in working on the JIT is even smaller. So we aim to train up people even if they don’t have any background in compilers.
Good: A teachable JIT
As I mentioned earlier, tracing was one decision to make the JIT easier to teach. There are a few other design decisions too, but those will be their own blog post. So I’m not talking about them here.
Could be improved: Performance
CPython 3.13’s JIT ranges from slower to the interpreter to roughly equivalent to the interpreter. Calling a spade a spade: CPython 3.13’s JIT is slow. It hurts me to say this considering I work on it, but I don’t want to sugarcoat my words here.
The argument at the time was that it was a new feature and we needed to lay the foundations and test the waters. You might think that surely, CPython 3.14’s JIT is a lot faster right? In some ways, the JIT has become faster, but only in select scenarios. The answer is again… complicated. When using a modern compiler like Clang 20 to build CPython 3.14, I often found the interpreter outperforms the JIT. The JIT only really starts reaching parity or outperforming the interpreter if we use an old compiler like GCC 11 to build the interpreter. However, IMO that’s not entirely fair to the interpreter, as we’re purposely limiting it by using a compiler we know is worse for it. You can see this effect very clearly on Thomas Wouter’s analysis here. Note that this is the geometric mean. So there are select workloads where the JIT does show a real speedup!
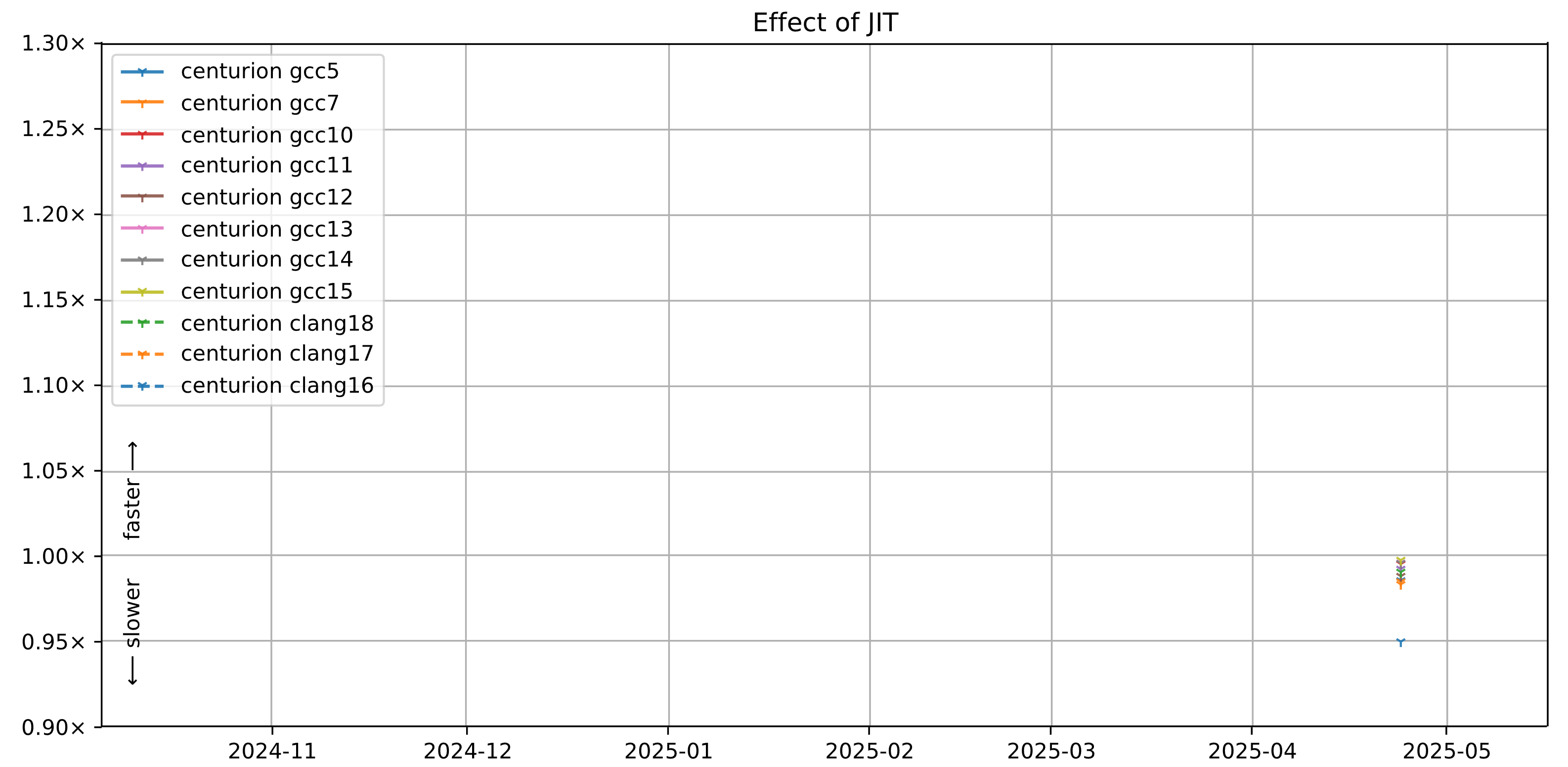 (Image credits to Thomas Wouters). Anything below 1.00x on the graph is a slowdown.
(Image credits to Thomas Wouters). Anything below 1.00x on the graph is a slowdown.
In short, the JIT is almost always slower than the interpreter if you use a modern compiler. This also assumes the interpreter doesn’t get hit by random performance bugs on the side (which has happened many times now). Note: this result only applies to our x64 benchmarks. I cannot conclude anything about AArch64, which has been improving over time.
In some cases, we do see significant speedups (up to ~20%) in certain benchmarks. Indicating that some progress has been made on 3.14. Which is a good thing! What we’re tackling is that the performance is a mixed bag and often not very predictable. In the richards benchmark, we see a ~20% speedup, but on the nbody benchmark, we see a ~10% slowdown on my system, and a smaller slowdown for the spectralnorm benchmark. All of these are known to be loop-heavy artificial benchmarks, which V8 has since ditched so in theory, they all should see a speedup, but they don’t, which is strange.
3.14 JIT Off:
richards: Mean +- std dev: 44.5 ms +- 0.5 ms
nbody: Mean +- std dev: 91.8 ms +- 3.5 ms
spectral_norm: Mean +- std dev: 90.6 ms +- 0.7 ms
3.14 JIT On:
richards: Mean +- std dev: 37.8 ms +- 2.4 ms
nbody: Mean +- std dev: 104 ms +- 2 ms
spectral_norm: Mean +- std dev: 96.0 ms +- 0.7 ms
System/Build configuration: Ubuntu 22.04, Clang 20.1.7, PGO=true, LTO=thin, tailcall=false. Tuned with pyperf system tune.
You might ask: why is the 3.14 JIT not much faster? The real answer, which again hurts me to say is that the 3.14 JIT has almost no major optimizer* features over 3.13. In 3.14, we were mostly expanding the existing types analysis pass to cover more bytecodes. We were also using that as a way to teach new contributors about the JIT and encourage contribution. In short, we were building up new talent. I personally think we were quite low on contributors at the start. I also had other commitments which made features that were supposed to go into the JIT not go in, which I’m sorry for. Personally, I think building up more talent over prioritizing immediate performance is the right choice for long-term sustainability of the JIT.
*optimizer = JIT optimizer, separate from the code generator. The code generator for x64 and AArch64 has seen improvements.
Could be improved: Inaccurate coverage
The initial media coverage of the 3.13 JIT got the numbers wrong by misinterpreting our results. There was this number of “2-9%” faster being spread around. I think the first major blog post that covered this was this one. Note that I’m friends with the author of that post and I’m not trying to say that they did a bad job. Conveying performance is a really hard job. One that I’m still struggling with myself. However, in good conscience, and as an aspiring scientist, I can’t stand by and watch people say the 3.13 JIT is “2-9%” faster than the intepreter. It’s really more nuanced than that (see section above). Often times, the CPython 3.13 JIT is a lot slower than the interpreter. Furthermore, the linked comment is that the 3.13 JIT is 2-9% faster than the tier 2 interpreter. That’s the interpreter that executes our JIT intermediate representation by interpreting it, which is super slow. It’s not comparing to the actual CPython interpreter.
I’ve seen other sources repeat this number too. It frustrates me a lot. The problem with saying the 3.13 JIT is faster is that it sets the wrong expectations. Again, users on the Python Discourse forum and privately have shared performance numbers where the JIT is a significant regression for them. This goes against the grain of what’s reported online. We do not have control over the numbers, but I still would like to clear the air on what the real expectation should be.
Ugly: None
If I had thought there were really ugly stuff, I wouldn’t be working on the JIT anymore :-).
Conclusion and looking forward
I’m still hopeful for the JIT. As I mentioned above, we’ve built a significant community around it. We’re now starting to pick up momentum on issues and new optimizations that could bring single-digit percentage speedups to the JIT in 3.15 (note: this is the geometric mean of our benchmarks, so real speedups might be greater or lesser). Brandt has already merged some optimizations for the JIT’s machine code. I don’t want to bring unwanted attention to the other efforts for the moment. Just know this: there are multiple parallel efforts to improve the JIT now that we have a bigger community around it that can enable such work. The road getting here has been tough, but there’s promise in our future. We also really need help testing the JIT and getting more data for it. Please try it out!
Correction notice
In a previous version of this blog post, I pointed out there were no major performance additions to the JIT in 3.14. When I said this, I was thinking of the JIT optimizer only, not the machine code generator. I am frankly underqualified to talk about the machine code generator. I have since updated the post to specify the optimizer. Furthermore, when I say major, I don’t meant to denigrate the efforts of our contributors. I had planned for certain major features to enter the CPython JIT in 3.14, but missed them due to my own lack of time. So I’m not pointing blaming anyone here other than myself.
The (lack-of) performance gains for the JIT are for architectures that I observed (mostly a range of x64 processors). It is possible that some architectures have real gains that I’m not aware of.
I also added some benchmarks run on my system, where I show a speedup in some workloads, but a slowdown in others.